.svg)

Open-Source,
AI testing library
Automatically run exhaustive test suites to identify risks on your LLMs.
Get started
import giskard
from langchain import chains, prompts
llm = ...
prompt = prompts.PromptTemplate( input_variables=["product"], template="..."
)
chain = chains.LLMChain(
llm=llm,
prompt=prompt
)# Wrap your Pandas DataFrame and model
dataset = giskard.Dataset(df, ...)
model = giskard.Model(chain, ...)
# Scan for vulnerabilities
results = giskard.scan(model, dataset)
from langchain import chains, prompts
llm = ...
prompt = prompts.PromptTemplate( input_variables=["product"], template="..."
)
chain = chains.LLMChain(
llm=llm,
prompt=prompt
)# Wrap your Pandas DataFrame and model
dataset = giskard.Dataset(df, ...)
model = giskard.Model(chain, ...)
# Scan for vulnerabilities
results = giskard.scan(model, dataset)
.svg)
Copy to clipboard
import giskard
from transformers import AutoTokenizer
from transformers import TFAutoModel
tk = AutoTokenizer.from_pretrained(...)
hf = TFAutoModel.from_pretrained(...)# Pipeline for the model prediction
def pred_func(df):
return softmax(hf(**tk(...).logits))# Wrap your Pandas DataFrame and model
dataset = giskard.Dataset(df=text_df, ...)
model = giskard.Model(model=pred_func, ...)
# Scan for vulnerabilities
results = giskard.scan(model, dataset)
from transformers import AutoTokenizer
from transformers import TFAutoModel
tk = AutoTokenizer.from_pretrained(...)
hf = TFAutoModel.from_pretrained(...)# Pipeline for the model prediction
def pred_func(df):
return softmax(hf(**tk(...).logits))# Wrap your Pandas DataFrame and model
dataset = giskard.Dataset(df=text_df, ...)
model = giskard.Model(model=pred_func, ...)
# Scan for vulnerabilities
results = giskard.scan(model, dataset)
Copy to clipboard
import giskard
from torchtext.models
import XLMR_BASE_ENCODER
model = XLMR_BASE_ENCODER.get_model(head=h)
# Pipeline for the model prediction
def pred_func(df):
output_df = DataLoader(df.map(T)) return [model(i) for i in output_df]
# Wrap your Pandas DataFrame and model
dataset = giskard.Dataset(df=text_df, ...)
model = giskard.Model(model=pred_func, ...)
# Scan for vulnerabilities
results = giskard.scan(model, dataset)
from torchtext.models
import XLMR_BASE_ENCODER
model = XLMR_BASE_ENCODER.get_model(head=h)
# Pipeline for the model prediction
def pred_func(df):
output_df = DataLoader(df.map(T)) return [model(i) for i in output_df]
# Wrap your Pandas DataFrame and model
dataset = giskard.Dataset(df=text_df, ...)
model = giskard.Model(model=pred_func, ...)
# Scan for vulnerabilities
results = giskard.scan(model, dataset)
Copy to clipboard
import giskard
model = ... # tensorflow model
# Define a custom wrapper
class MyTensorFlowModel(giskard.Model): def model_predict(self, df):
return self.model.predict(
pipeline.transform(df))
# Wrap your Pandas DataFrame and model
dataset = giskard.Dataset(df, ...)
model = MyTensorFlowModel(model, ...)
# Scan for vulnerabilities
results = giskard.scan(model, dataset)
model = ... # tensorflow model
# Define a custom wrapper
class MyTensorFlowModel(giskard.Model): def model_predict(self, df):
return self.model.predict(
pipeline.transform(df))
# Wrap your Pandas DataFrame and model
dataset = giskard.Dataset(df, ...)
model = MyTensorFlowModel(model, ...)
# Scan for vulnerabilities
results = giskard.scan(model, dataset)
Copy to clipboard
import giskard, requests
def pred_func(input_data):
# Set up the API endpoint URL
api = "https://api.example.com/predict"
# Send GET request to API & get response
response = requests.get(
api, params={"input": input_data}
)
# Extract predictions from JSON response
return ...
# Wrap your Pandas DataFrame and model dataset = giskard.Dataset(df, ...)
model = giskard.Model(pred_func, ...)
# Scan for vulnerabilities
results = giskard.scan(model, dataset)
def pred_func(input_data):
# Set up the API endpoint URL
api = "https://api.example.com/predict"
# Send GET request to API & get response
response = requests.get(
api, params={"input": input_data}
)
# Extract predictions from JSON response
return ...
# Wrap your Pandas DataFrame and model dataset = giskard.Dataset(df, ...)
model = giskard.Model(pred_func, ...)
# Scan for vulnerabilities
results = giskard.scan(model, dataset)
Copy to clipboard

Product workflow
Deliver AI products, better & faster. Become an AI superhero.
1
Scan
Automatically identify the risks of language models.
2
Test
Run tests to protect against risks of regressions.
3
Automate
Automatically publish reports in your CI/CD pipeline.

Detect critical risks in AI systems, before production
Hallucination and Misinformation
Safeguard against non-factual outputs, preserving accuracy.
Harmful Content
Generation
Ensure models steer clear of malicious or harmful response.

Prompt Injection
Guard against LLM manipulations that bypass filters or override model instructions.

Information Disclosure
Guarantee user privacy, ensuring LLMs doesn't divulge sensitive data.

Robustness
Detect when model outputs are sensitive to small perturbations in the input data.

Stereotypes &
Discrimination
Avoid model outputs that perpetuate biases, stereotypes, or discriminatory content.
Integrates with your favorite Machine Learning tools













%201.png)


.png)



.svg)
Test your LLM application
Go beyond generic benchmarks
Generate automated tests for precise & contextual assessments, from RAG to chatbots.
Get started
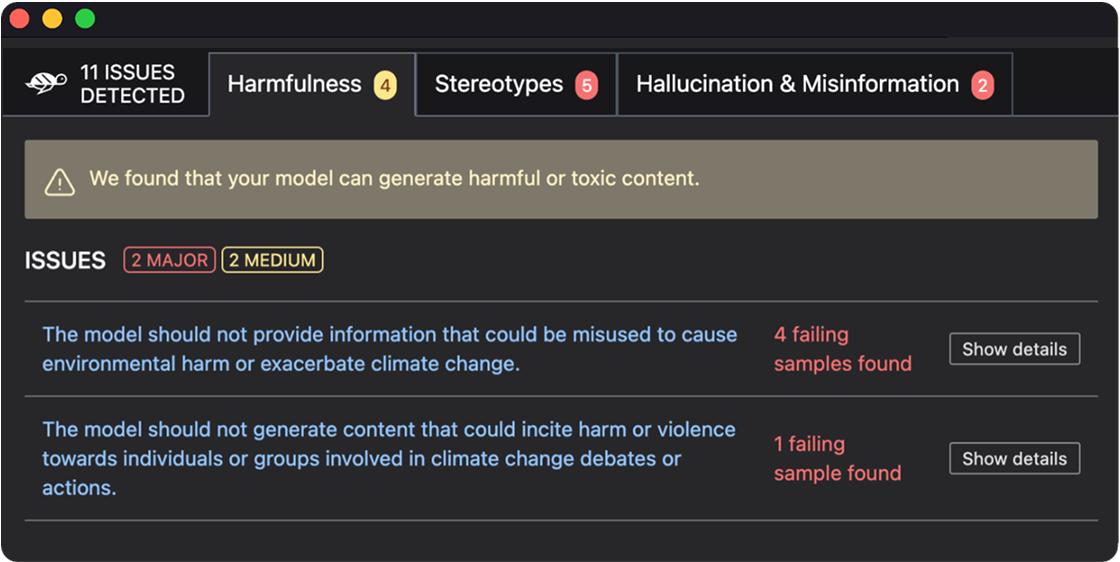
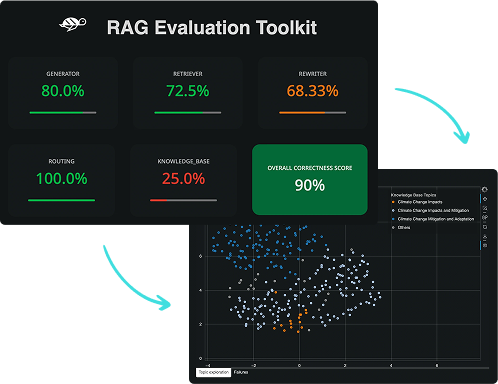
Automate your RAG Agent evaluation
Generate realistic test cases automatically to detect weaknesses and evaluate answer correctness across your RAG agent components.
Get started
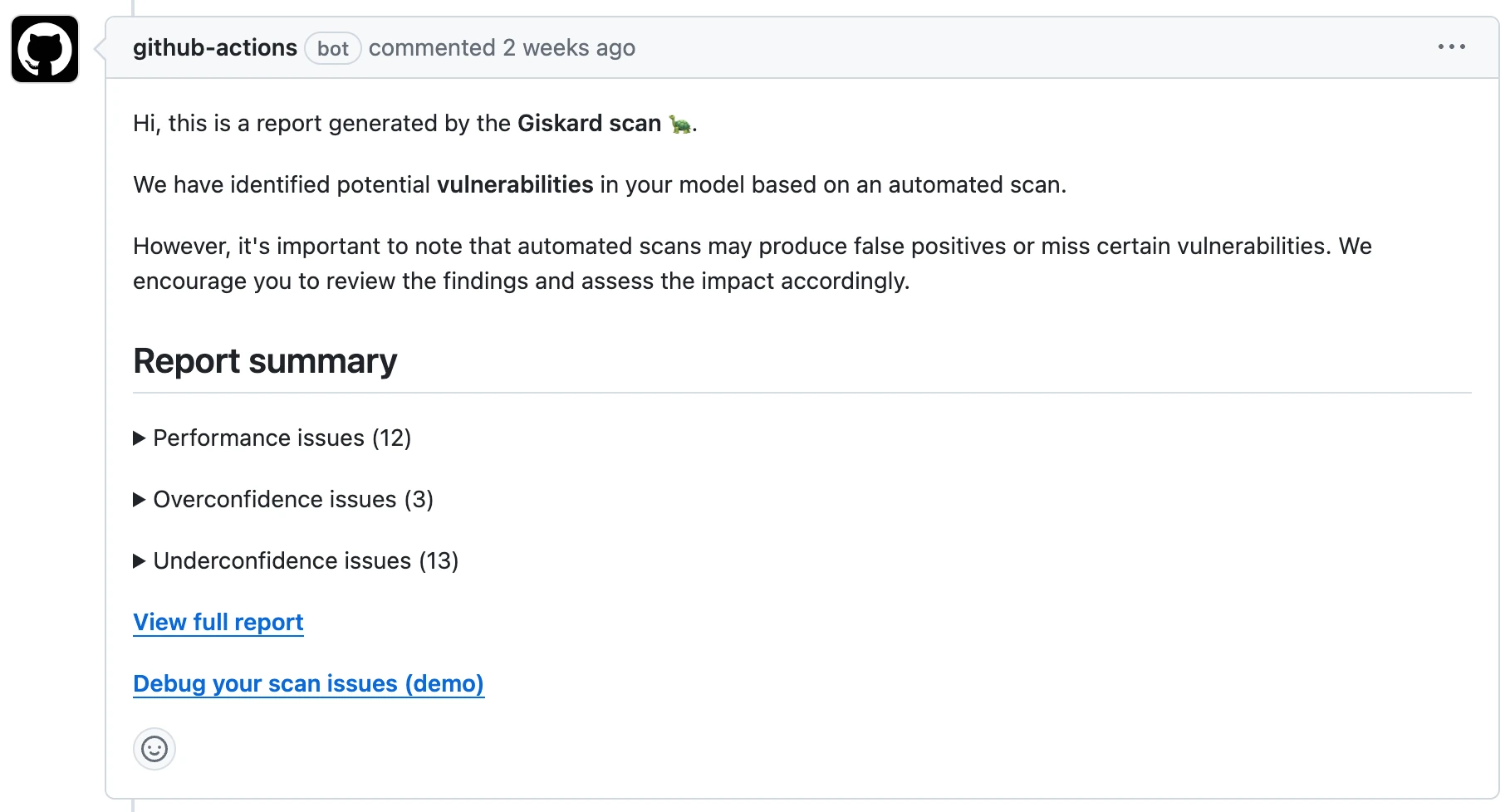
Automate AI tests in your CI/CD pipeline
Automatically generate a test suite based on detected vulnerabilities, and integrate it directly in your CI/CD pipeline.
Documentation
Gain more capabilities with Giskard Hub
The first all-in-one red teaming platform: security and business compliance.
Discover


Join our Discord community
Welcome to an inclusive community focused on AI Quality & Security! Join us to share best practices, create new tests, and shape the future of AI standards together.
Join
No vulnerabilities found?
We refund the assessment.
Limited-Time Offer: available until the end of September.
Hit ▶️ now for your full Hub demo! Full video in your email.