
.svg)







Introduction to SHAP (SHapley Additive exPlanations)
Understanding the inner workings of machine learning models is becoming increasingly crucial, especially in scenarios where model explainability holds equal importance to its performance. In domains like medical diagnostics and finance, Explainable AI plays a pivotal role, providing invaluable insights to both doctors and patients, and fostering trust in critical financial decisions.
While some models, like linear regression, offer interpretability through feature importances derived from their coefficients, the advent of modern state-of-the-art solutions has led to a proliferation of complex models, such as deep neural networks, which pose significant challenges in interpretation. In such complex systems, the quest for understanding the model's decision-making process has led to the emergence of innovative techniques, and one of the most promising approaches is the SHAP (SHapley Additive exPlanations) framework. In this article, we will delve into the power of SHAP in shedding light on the inner workings of these enigmatic black-box models, empowering users with unprecedented insights into the factors that drive their predictions.
What are the SHAP values?
The SHAP framework represents a revolutionary advancement in the field of Explainable AI, offering a unique methodology to unveil the influence of individual features on a model's predictions. In contrast to conventional black-box techniques, SHAP introduces a transparent and interpretable approach that facilitates a deeper understanding of complex machine learning models' decision-making processes. By breaking down predictions into feature contributions, SHAP equips data scientists with a powerful tool to navigate intricate models, extract valuable insights, and uphold model fairness. This transformative framework has the potential to reshape the way we comprehend and leverage AI models in various domains.
How SHAP values are calculated?
The framework computes SHAP values by exploring all feature combinations and determining the average marginal contribution of each feature. This systematic approach guarantees fairness and impartial feature attributions, empowering data scientists with a holistic understanding of how each feature influences the model's predictions.
SHAP Python library
The practical implementation of the SHAP values becomes achievable with the aid of the SHAP Python library, which provides a comprehensive set of robust functions for model interpretation. Whether it's computing Shapley values, creating feature importance plots, or performing other vital tasks, this Python framework empowers data scientists with indispensable tools to unravel the mysteries underlying their machine learning models.
Explaining Machine Learning models using SHAP
Use Case 1: SHAP values effectively diagnose wrong predictions
Identifying the reasons behind incorrect predictions is crucial when dealing with machine learning models, because it helps improve model performance, gain insights into model behavior, and increase overall trust in the model's predictions.
By analyzing the SHAP values, developers and data scientists can pinpoint which features or combinations of features may be responsible for the incorrect prediction. Understanding this information facilitates model debugging and highlights areas for improvement. SHAP values can indeed guide feature engineering efforts and lead to more informative feature representations, or even indicate the need to remove irrelevant or noisy features.
In order to illustrate this point, let's check the SHAP values one by one for some incorrect predictions. We are going to analyze the model trained on the German credit scoring dataset to predict whether the customer can be given a credit or not. The cause of wrong prediction is largely due to account_check_status, i.e. bank account balance, as shown in the screenshot below. Several other incorrect examples follow the same pattern: often the predictions are incorrect when there are less than 200 Deutsche Marken (DM) in the checking account.
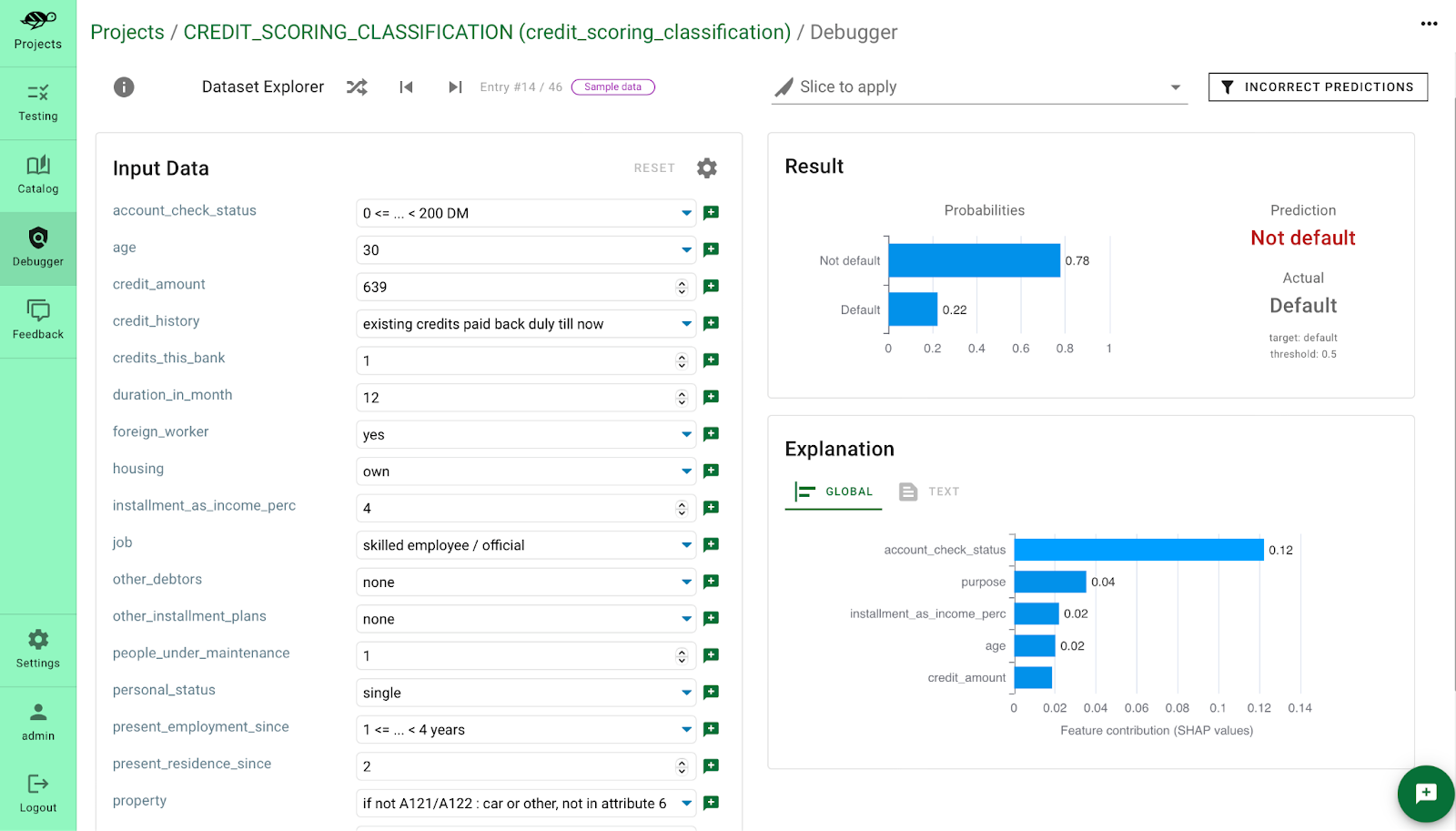
This insight is very important since we have detected a data slice that is possibly responsible for incorrect predictions. Let’s check this on the whole dataset to make sure this insight is generalizable to the whole dataset.
After saving this data slice (account_check_status < 200 DM), we can easily run a test to check if the accuracy of the model is low on this data slice. As you can see in the screenshot below, the accuracy of the model on this slice is only 57% while it’s equal to 77% on the whole dataset.

SHAP values helped us detect an important incorrect pattern in the model. Debugging this pattern requires a better understanding of this data slice (credit demanders who have less than 200 DM in their checking account). It is a good habit to consult business stakeholders for advice on understanding these credit demanders better. Domain knowledge can enable the data scientist to do the right feature engineering to better qualify these demanders or create special decision rules for these data slices.
Use Case 2: SHAP values are effective in identifying fairness biases
Models can learn patterns that are unfair towards minority groups, particularly when the data is biased against them. Detecting fairness issues can be challenging as it requires comprehending which features are responsible for the model's behavior.
By using SHAP values, it becomes possible to detect and address potential sources of bias. When a sensitive variable (such as belonging to a minority group) has a high SHAP contribution to a decision, the data scientist should challenge the decision to make sure it is in line with the organization's policy. Under the EU AI Act for instance, it's even mandatory to check if some ML decisions are not biased.
Let’s consider a model, which predicts, if the annual wage is below or above 50K from the Adult Census Data. After looking at the predictions, we notice a clear pattern: When the predicted wage is "<=50K," the feature "gender" shows a significant SHAP value, particularly for females.

However, when the person is male, there is often no meaningful attribution of gender to the prediction, as seen in the example below.
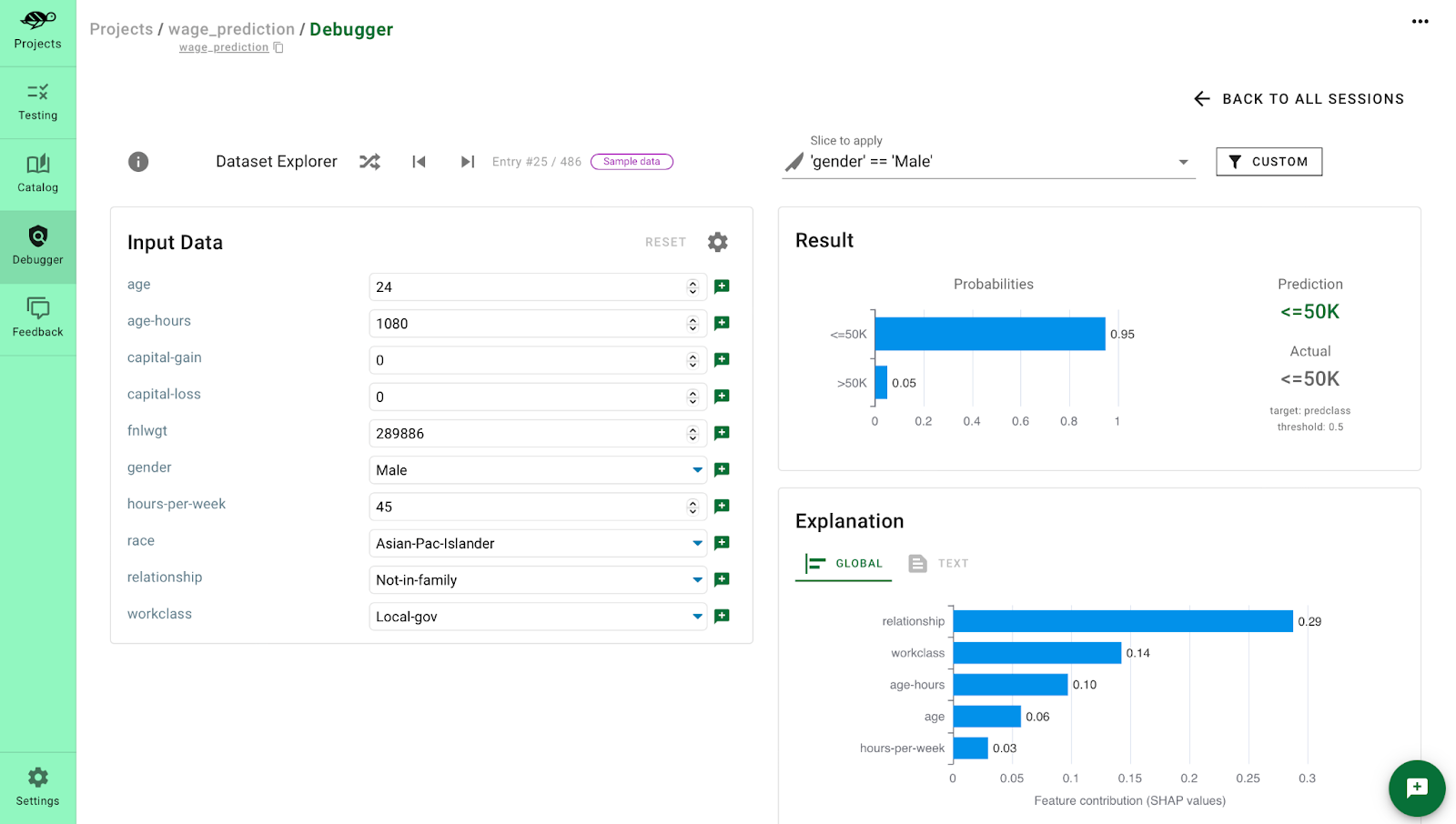
Having this in mind, we can analyze the model's behavior between males and females by using the Disparate Impact test, which measures whether two different groups are treated similarly by the model.

The result is very clear. The model exhibits significant bias in predicting lower wages for females. SHAP correctly identified that gender has a substantial impact on underpayment for females but not for males. So, it is obvious that the model highly takes into account a person's gender when making predictions.
In real business scenarios the gender must not have high importance, and the model output should not be based on it, because it introduces discriminative behavior. One must consider calibrating the model to make it less sensitive to the person’s sex, or augment training data in a way that makes this feature less important in the decision-making process.
Use Case 3: SHAP values help to identify spurious correlations
Spurious correlation in machine learning occurs when a feature and the model prediction seem statistically correlated, but their relationship is coincidental or influenced by external factors, rather than representing a meaningful or causal connection.. In other words, the relation between the feature and the model prediction is not based on a true cause-and-effect relationship. This can be caused by confounding variables, data noise or overfitting.
SHAP values are valuable for detecting spurious relationships. When a feature has a high SHAP contribution but lacks a business relationship with the model, data scientists must decide whether to remove the feature or augment the dataset with more samples containing the problematic feature value. This is essential to ensure that the model does not learn noisy or overfitted patterns and to create more explainable models.
Let's consider a sentiment prediction model trained to categorize tweets as positive, neutral, or negative. After investigating the model's performance, we discovered a set of problematic tweets that are sarcastic by nature, but the model failed to appropriately account for this aspect. As a result, words like "thanks," "excited," "good," etc., receive a significantly positive SHAP value, causing the model to misclassify sarcastic tweets with genuinely negative connotations as having a positive sentiment.

In this example we see that the message has truly negative sentiment, but due to the word “thanks” the model predicted a positive sentiment. This is because the word has a huge impact on the model outcome, which is clearly reflected by the huge SHAP value.
We can further compare model performance on the full dataset versus the slice of tweets containing above mentioned sarcastic words (thank, excite, good).

The current model exhibits confusion between sarcastic tweets and non-sarcastic ones. By assigning high positive importance to controversial words, SHAP has shown that the model overfitted in terms of treating them only as non-sarcastic. This is a great example of spurious correlation between input feature and model’s output. Although in the real world the ratio of occurrences between two types of tweets is indeed really big, which is reflected in the dataset, and has caused overfitting, we need to consider augmenting training data with more sarcastic examples with different sentiment to allow the model to generalize on such samples.
Conclusion
The SHAP framework has emerged as a transformative tool in the quest for explainable AI. By providing transparent insights into complex machine learning models, SHAP empowers data scientists to make informed decisions, enhance model accuracy, and ensure model fairness. Embracing SHAP's feature importance and explanations leads to a more interpretable and trustworthy AI future, where the once-unfathomable becomes clear and accountable. As we continue to unlock the mysteries of the black box, the SHAP framework stands as a guiding light, illuminating the path towards reliable and understandable AI solutions.


