
.svg)


.png)




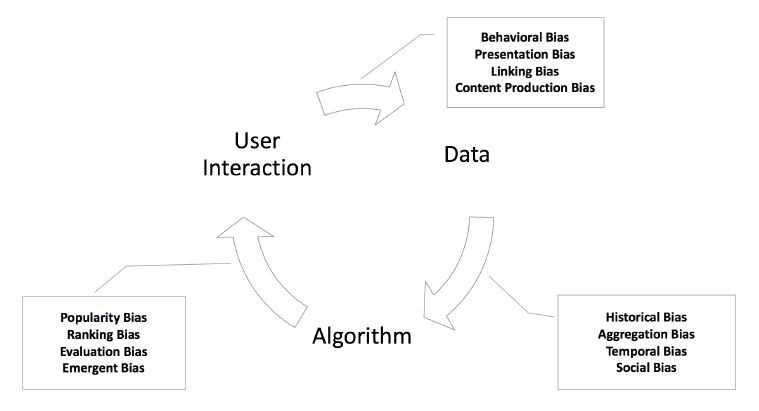
Research papers list plenty of bias sources in AI models. One review that particularly interests us is the one from Mehrabi (2019). It formalizes the AI development process as a feedback loop with three components:
- Data
- Algorithm
- End-user
Along this circular process, multiple biases can arise:
With the widespread use of AI systems and applications in our everyday lives, it is important to take fairness issues…
1. Between data and algorithm
Data scientists train models in a social world with many imperfections: discriminations, social inequalities amongst other power relations. These imperfections can induce hidden biases inside the model despite data scientists’ efforts to develop good models (Suresh & Guttag, 2019).
2. Between algorithm and end-user
AI models are used by humans to make decisions, often through user interfaces. For instance, a credit scoring algorithm computes the default probability to help bank advisors accept or deny loan requests. Depending on the advisor and the design of the interface, the same probability can lead to very different decisions (Friedman & Nissenbaum, 1996).
3. Between end-user and data
In a production system, end-users can produce behavioral data that are fed back to the model. These behaviors can vary depending on enunciation contexts. For example, one single user can have very different behaviors across social networks. Consequently, models are only valid in a specific context and can fail to generalize (Baeza-Yates, 2018).
At Giskard, we help AI professionals to identify these hidden biases. In an upcoming series of posts, we are going to deep dive into the multiple categories of biases and how to address them.
Want to know more? ✋ Contact us at [email protected]
Bibliography
- Harini Suresh and John V Guttag. 2019. A Framework for Understanding Unintended Consequences of Machine Learning.
- Batya Friedman and Helen Nissenbaum. 1996. Bias in Computer Systems.
- Ricardo Baeza-Yates. 2018. Bias on the Web.





